
結論から言うと、ChatGPT-5はメモリを何倍食うのかは正しく理解して活用すれば資産形成の強力な味方になります。本記事では初心者にもわかりやすく、押さえるべきポイントと具体的な手順を整理しました。
※本ページはプロモーションを含みます。アフィリエイト広告を掲載しており、ご紹介するサービスが成約した際に当サイトに報酬が発生することがあります。
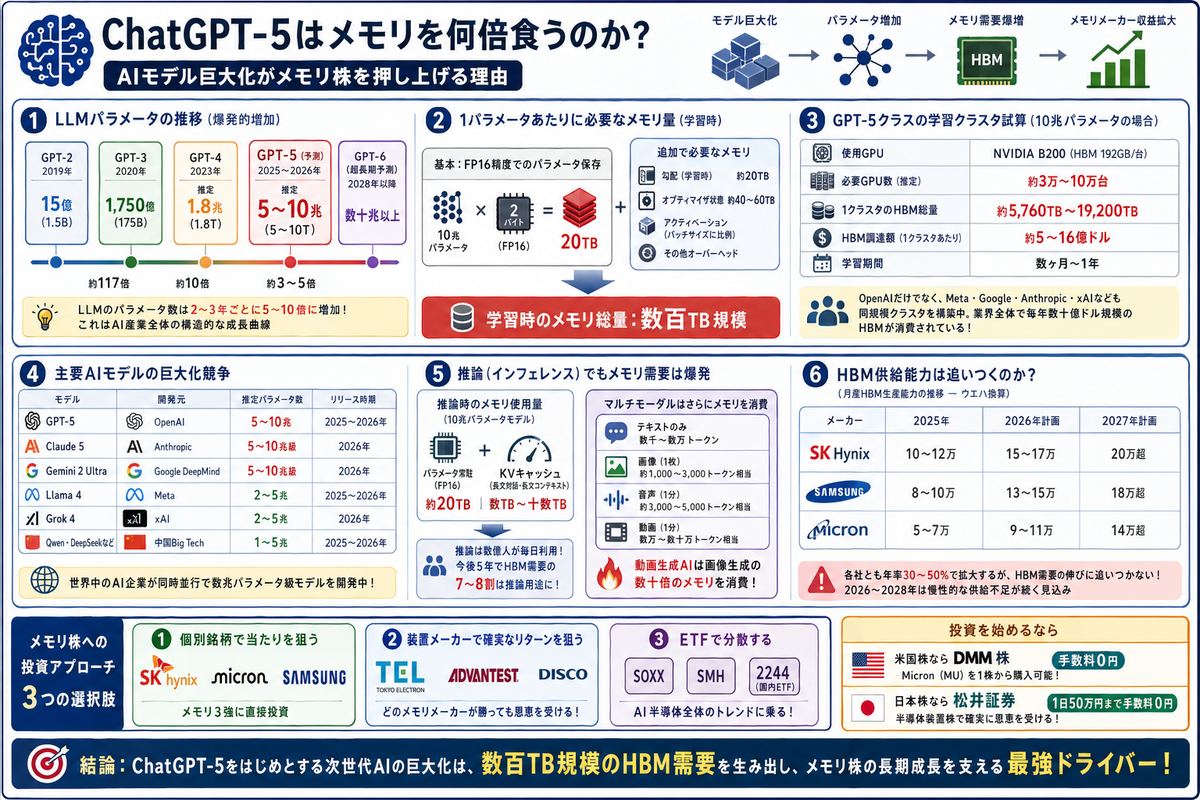
AIの「胃袋」はどこまで大きくなるのか
ChatGPTが登場してからわずか3年。AIモデルのサイズは、その間に信じがたいスピードで膨張し続けています。GPT-3(1,750億パラメータ)、GPT-4(推定1.8兆)、そして次世代のGPT-5は業界推定で5兆〜10兆パラメータ規模とされています。
このパラメータ数の膨張は、単なる技術スペックの話ではありません。必要なメモリ(HBM)の量も同じペースで増加しており、AI業界全体のHBM調達コストが爆発的に拡大しています。そして、このコストはそのままメモリ3強(SK Hynix・Samsung・Micron)の売上として積み上がっています。
本記事の結論:ChatGPT-5をはじめとする次世代LLMの巨大化は、AI開発のコスト構造を根本的に変える。モデル1個の学習に必要なHBMは数百TB規模となり、メモリ供給がAI進化のボトルネックになりつつある。これは需要側からメモリ株を押し上げる、最も強力かつ構造的なドライバーである。
LLMパラメータの爆発的増加|GPT-3からGPT-5まで
主要LLMのパラメータ数の推移を整理します。
| モデル | リリース年 | パラメータ数 | 前世代比 |
|---|---|---|---|
| GPT-2 | 2019年 | 15億(1.5B) | ― |
| GPT-3 | 2020年 | 1,750億(175B) | 約117倍 |
| GPT-4 | 2023年 | 推定1.8兆(1.8T) | 約10倍 |
| GPT-5(予測) | 2025〜2026年 | 推定5〜10兆 | 約3〜5倍 |
| GPT-6(超長期予測) | 2028年以降 | 数十兆以上 | ― |
この表が示すのは、LLMのパラメータ数は2〜3年ごとに5〜10倍に増加しているという事実です。これが短期的なトレンドではなく、AI産業全体の構造的な成長曲線であることは、Meta・Google・Anthropicなど他社モデルも同じペースで膨張していることから分かります。
1パラメータあたりに必要なメモリ量
パラメータ数が必要メモリ量にどう変換されるかを解説します。
基本計算:FP16精度での必要メモリ
必要メモリ(パラメータ保存)
= パラメータ数 × 精度(バイト)
= 10兆パラメータ × 2バイト(FP16)
= 20TB
ただし、これは「パラメータを保存するだけ」の最小容量です。実際の学習や推論では、さらに以下のメモリが必要です。
| 用途 | 追加メモリ(目安) | 用途説明 |
|---|---|---|
| 勾配(学習時) | パラメータと同容量 | バックプロパゲーション用 |
| オプティマイザ状態(Adam等) | パラメータの2〜3倍 | 学習履歴の保持 |
| アクティベーション | バッチサイズに比例 | 中間層の出力保持 |
| KVキャッシュ(推論時) | コンテキスト長に比例 | 長文処理の高速化 |
実際の学習に必要なメモリ総量
10兆パラメータモデルの学習に必要なメモリ
= パラメータ(20TB) + 勾配(20TB) + オプティマイザ(60TB) + アクティベーション
≒ 数百TB(合計)
この「数百TB」というスケールは、1基のGPUでは到底収まりません。そこで数万台のGPUを並列動作させ、それぞれに数十〜数百GBのHBMを持たせて分散学習を行う構成が必要になります。
GPT-5の学習クラスタに必要なHBM総量を試算
ここでは、GPT-5クラスの10兆パラメータモデルを学習するために必要なGPU数・HBM総量を試算してみます。
| 項目 | 数値 |
|---|---|
| モデル規模 | 10兆パラメータ |
| 使用GPU | NVIDIA B200(HBM 192GB/台) |
| 必要GPU数(推定) | 約3万〜10万台 |
| 1クラスタのHBM総量 | 約5,760TB〜19,200TB |
| HBM調達額(1クラスタあたり) | 約5〜16億ドル |
| 学習期間 | 数ヶ月〜1年 |
この試算は1クラスタ分です。しかもOpenAIだけでなく、Meta(Llama 4・5)、Google(Gemini 2・Ultra)、Anthropic(Claude 5)、xAI(Grok 4)なども並行して同規模のモデルを学習しています。つまり業界全体で毎年数十億ドル規模のHBMが消費されている計算になります。
AI巨大化の恩恵を受けるMicron株をDMM株で購入
米国の唯一のHBMメーカーMicron(MU)は、AIモデル巨大化の直接的な受益者です。DMM株なら米国株取引手数料0円で、最短即日の口座開設が可能です。
※広告・PR
Llama 4 / Gemini 2 / Claude 5でも同じ構造
GPT-5だけでなく、競合他社のLLMも同じスケールで巨大化しています。
| モデル | 開発元 | 推定パラメータ数 | リリース時期 |
|---|---|---|---|
| GPT-5 | OpenAI | 5〜10兆 | 2025〜2026年 |
| Claude 5 | Anthropic | 5〜10兆級 | 2026年 |
| Gemini 2 Ultra | Google DeepMind | 5〜10兆級 | 2026年 |
| Llama 4 | Meta | 2〜5兆 | 2025〜2026年 |
| Grok 4 | xAI | 2〜5兆 | 2026年 |
| 中国系(Qwen・DeepSeek等) | 中国Big Tech | 1〜5兆 | 2025〜2026年 |
つまり、GPT-5だけで話が終わるわけではなく、世界中のAI企業が同時並行で数兆パラメータ級モデルを開発しています。それぞれが数万GPUクラスタを必要とし、それぞれが数億ドル規模のHBMを消費します。
推論(インフェレンス)でもメモリが不足する時代
AIのメモリ需要は「学習」だけで終わりません。実は、多くの投資家が見落としているのが推論(インフェレンス)におけるメモリ消費です。
推論時のメモリ使用量
推論時にも、モデルのパラメータ全体をGPUメモリに常駐させる必要があります。10兆パラメータモデルを推論するには、FP16で約20TB、量子化して8bit/4bitに縮めても数TBのHBMが必要です。
KVキャッシュの爆発
ChatGPTで長文対話や長文ドキュメント分析を行うと、コンテキスト長に比例してKVキャッシュと呼ばれる中間データが肥大化します。最新モデルでは100万トークン以上のコンテキストをサポートしており、これだけで1推論あたり数GBのメモリを追加消費します。
推論需要は学習の10倍以上になる可能性
モデル開発は基本的に1社のAI企業が行いますが、推論は数億人のユーザーがアクセスするたびに発生します。ChatGPTだけでも週次アクティブユーザー数億人、1日の推論回数は数十億回規模です。
業界アナリストの間では、「今後5年でAI用HBM需要の7〜8割は推論用途が占める」という見方も出ています。つまり、学習用HBM市場の何倍もの規模で推論用HBM需要が立ち上がる構図です。
マルチモーダルAIはさらにメモリを食う
次世代AIは、テキストだけでなく画像・音声・動画を同時に処理する「マルチモーダル」が標準になります。マルチモーダルAIはメモリ消費がさらに大きくなります。
| モダリティ | 1リクエストあたりトークン数 | メモリ消費の特徴 |
|---|---|---|
| テキストのみ | 数千〜数万 | 比較的軽量 |
| 画像(1枚) | 約1,000〜3,000トークン相当 | 高解像度ほど増加 |
| 音声(1分) | 約3,000〜5,000トークン相当 | 長時間でリニア増加 |
| 動画(1分) | 数万〜数十万トークン相当 | メモリ消費が爆発的 |
動画生成AI(OpenAI Sora、Google Veo、Runwayなど)は、画像生成AIの数十倍のメモリを消費します。動画生成市場の拡大に伴い、HBM需要はさらに上振れする構造です。
メモリ生産能力は追いつくのか?
ここまでの議論で、AI需要側のHBM消費は指数関数的に増加することが分かりました。では、供給側(メモリ3強)の生産能力はこれに追いつけるのでしょうか。
| メーカー | 2025年HBM生産能力 | 2026年計画 | 2027年計画 |
|---|---|---|---|
| SK Hynix | 月産10〜12万ウエハ | 月産15〜17万ウエハ | 月産20万ウエハ超 |
| Samsung | 月産8〜10万ウエハ | 月産13〜15万ウエハ | 月産18万ウエハ超 |
| Micron | 月産5〜7万ウエハ | 月産9〜11万ウエハ | 月産14万ウエハ超 |
各社とも年率30〜50%で生産能力を拡大する計画ですが、それでもHBM需要の伸びに追いつかないと見られています。特にHBM4以降は16層スタックの歩留まりの制約で、実効生産量はさらに絞られる可能性があります。
結論として、2026〜2028年はHBMが慢性的な供給不足の状況が続く見込みです。供給不足はメーカーの価格決定力を強め、利益率を高水準に保つ要因となります。
メモリ株への投資チャンス|3つのタイミング
AIモデル巨大化を背景にメモリ株へ投資する場合、以下の3つのアプローチが考えられます。
アプローチ1:個別銘柄で「当たり」を狙う
SK Hynix、Micron、Samsungの3強に個別投資する方法。先行しているSK Hynix、値上がり余地の大きいMicronなどが選択肢です。
アプローチ2:装置メーカーで「確実な」リターンを狙う
どのメモリメーカーが勝っても、HBM製造に必要な装置を供給する東京エレクトロン・アドバンテスト・ディスコは必ず恩恵を受けます。リスク分散の観点で有利です。
アプローチ3:ETFで「分散」する
半導体ETF(SOXX、SMH)や、国内上場の半導体ETF(2244など)に投資する方法。メモリ単独にはならないが、AI半導体全体のトレンドに乗れます。
日本の半導体装置株を買うなら松井証券
東京エレクトロン(8035)、アドバンテスト(6857)、ディスコ(6146)などの日本半導体装置株は、どのメモリメーカーが勝っても恩恵を受ける「ピッケルとシャベル」銘柄です。松井証券なら1日50万円まで取引手数料無料です。
※広告・PR
初心者におすすめの買い方
メモリ株に投資してみたいが、個別株は不安という方には以下のステップがおすすめです。
- Step1:DMM株で口座開設(無料・最短即日)
- Step2:Micron(MU)を1株(約1.5万円)から購入してみる
- Step3:慣れてきたら松井証券で日本の半導体装置株も追加
- Step4:さらに余裕があれば韓国メモリ株(SK Hynix・Samsung)も検討
米国メモリ株(Micron)を1万円台から始める
DMM株なら米国株取引手数料0円。Micron(MU)は1株約100ドル前後なので、1万5千円程度から購入できます。
※広告・PR
▼ 投資アプリでサクッと始めるならTOSSY
※広告・PR かんたんステップでアカウント登録
Q&A
Q. ChatGPT-5のパラメータ数はどのくらいですか?
A. OpenAIは公式にパラメータ数を公開していませんが、業界推定ではGPT-5は約5〜10兆パラメータと見られています。GPT-3の175B、GPT-4の推定1.8Tと比較して、1世代で約5倍のスケールです。
Q. 1パラメータに必要なメモリはどのくらいですか?
A. FP16精度で1パラメータあたり2バイト、推論時のKVキャッシュなどを含めると実効的に4〜8バイト必要です。10兆パラメータのモデルなら、学習時に数百TBのメモリ、推論時でも数十TBのHBMが必要です。
Q. GPT-5の学習にはGPUが何台必要ですか?
A. 業界推定では、GPT-5クラスのモデル学習には数万〜10万台規模のNVIDIA H100/H200/B200 GPUが必要です。1クラスタあたり数TB〜数十TBのHBMが消費され、学習完了まで数ヶ月稼働します。
Q. 推論(インフェレンス)でもメモリは不足しますか?
A. はい。推論時も全モデルパラメータをGPUメモリに常駐させる必要があり、マルチターン対話や長文コンテキストではKVキャッシュが肥大化します。結果として、推論向けGPUクラスタも学習と同様にHBMを大量消費します。
Q. AIモデル巨大化はメモリ株にどう影響しますか?
A. AIモデルのパラメータは指数的に増加しており、1世代ごとに必要HBM量が数倍になります。これはメモリ3強(SK Hynix・Samsung・Micron)の売上を構造的に押し上げる要因であり、メモリ株の長期成長ドライバーです。
まとめ
AIモデルの巨大化は、メモリ株にとって「需要側からの構造的な追い風」です。GPT-5、Claude 5、Gemini 2、Llama 4など、世界中の主要LLMが同時並行で数兆パラメータ級へと進化しており、それぞれが数億ドル規模のHBMを消費します。
- LLMパラメータは2〜3年で5〜10倍に増加し続ける
- 10兆パラメータモデルの学習に必要なHBMは数百TB
- 推論市場は学習の10倍以上に拡大する見込み
- マルチモーダル・動画生成AIでメモリ消費はさらに増大
- 供給側の生産能力は需要の伸びに追いつかず、価格は高水準で推移
この構造的需要増の恩恵を最もダイレクトに受けるのが、メモリ3強とその装置メーカーです。DMM株と松井証券の口座を開設しておけば、米国メモリ株と日本装置株の両方にアクセスでき、AI時代のメモリ株ブームに機動的に乗ることができます。
▼ どちらの口座も手数料無料・最短即日開設
米国株(Micron/NVDA/ETF)なら
日本株(東京エレクトロン/アドバンテスト)なら
※広告・PR
※本記事は情報提供を目的としており、投資の勧誘を目的とするものではありません。投資にはリスクが伴います。投資判断はご自身の責任で行ってください。
※GPT-5のパラメータ数、必要GPU数、HBM総量の試算は業界アナリスト推定に基づく概算です。実際の数値はOpenAI等の各社公式発表により異なる場合があります。

